二叉树
三种遍历
前中后序遍历的区别其实就是根节点的位置不同:
前序遍历是 根–左子–右子
中序遍历是 左子–根–右子
后序遍历是 左子–右子–根
前序遍历(Preorder Traversal)
顺序 :根节点 → 左子树 → 右子树特点 :先访问根节点,再递归遍历左右子树。示例 :
前序遍历结果:1, 2, 4, 5, 3
中序遍历(Inorder Traversal)
顺序 :左子树 → 根节点 → 右子树特点 :先遍历左子树,再访问根节点,最后遍历右子树。示例 :4, 2, 5, 1, 3
后序遍历(Postorder Traversal)
顺序 :左子树 → 右子树 → 根节点特点 :先递归遍历左右子树,最后访问根节点。示例 :4, 5, 2, 3, 1
完全二叉树
完全二叉树的性质:
对于任意一个节点i i i i 2 \dfrac{i}{2} 2 i 2 × i 2 \times i 2 × i 2 × i + 1 2 \times i+1 2 × i + 1
树状数组
可以高效率地查询和维护前缀和 (或区间和);当序列是动态变化的时,如果改变其中一个元素a i a_i a i O ( n ) O(n) O ( n ) O ( l o g 2 n ) O(log_2n) O ( l o g 2 n )
lowbit(x)
找x的二进制数的最后一个1对应的十进制是多少,找到的数一定是2的次幂。
lowbit(x) = x & -x
例如,lowbit(5) = 5 & -5 = 1,
lowbit(6) = 6 & -6 = 2,lowbit(8) = 8 & -8 = 8
编码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #incldue <bits/stdc++.h> using namespace std;const int N = 1000 ;#define lowbit(x) ((x) & -(x)) int tree[N] = {0 };void update (int x,int d) while (x <= N){ tree[x] += d; x += lowbit (x); } } int sum (int x) int ans = 0 ; while (x > 0 ){ ans += tree[x]; x -= lowbit (x); } return ans; } int a[11 ] = {0 ,4 ,5 ,6 ,7 ,8 ,9 ,10 ,11 ,12 ,13 } int main (){ for (int i=1 ;i<=10 ;i++) update (i,a[i]); cout << "old:[5,8] = " << sum (8 ) - sum (4 ) << '\n' ; update (5 ,100 ); cout << "new:[5,8] = " << sum (8 ) - sum (4 ) << '\n' ; return 0 ; }
线段树
线段树的核心思想是分治,大区间的解可以由小区间的解合并而来,总复杂度为O ( n l o g n ) O(nlogn) O ( n l o g n )
区间最值问题。长为n n n a a a
求区间[ i , j ] [i,j] [ i , j ]
修改a [ k ] a[k] a [ k ] x x x
区间和问题。长为n n n a a a [ i , j ] [ i , j ] [ i , j ]
线段树建立在二叉树上,每次分治左右子树各一半,能利用二叉树的许多性质。
PS:对于任意一个节点i i i i 2 \dfrac{i}{2} 2 i 2 × i 2 \times i 2 × i 2 × i + 1 2 \times i+1 2 × i + 1
考察每个线段[ L , R ] [L,R] [ L , R ] L L L R R R
L = R L=R L = R L < R L<R L < R [ L , M ] [L,M] [ L , M ] [ M + 1 , R ] [M+1,R] [ M + 1 , R ] M = ( L + R ) / 2 M = (L+R)/2 M = ( L + R ) /2
线段树的构造:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int tree[N*4 ]; int ls (int p) return p<<1 ;} int rs (int p) return p<<1 |1 ;} void push_up (int p) tree[p] = tree[ls (p)] + tree[rs (p)]; } void build (int p,int pl,int pr) if (pl == pr) {tree[p] = a[pl];return ;} int mid = (pl+pr) >> 1 ; build (ls (p),pl,mid); build (rs (p),mid+1 ,pr); push_up (p); }
区间查询:
1 2 3 4 5 6 7 int query (int L,int R,int p,int pl,int pr) if (L<=pl && R>=pr) return tree[p]; int mid = (pl+pr) >> 1 ; if (L<=mid) res += query (L,R,ls (p),pl,mid); if (R>=mid+1 ) res += queru (L,R,rs (p),mid+1 ,pr); return res; }
Layz-Tag:
线段树的节点t r e e [ i ] tree[i] t ree [ i ] i i i t a g [ i ] tag[i] t a g [ i ] i i i O ( l o g 2 n ) O(log_2n) O ( l o g 2 n ) m m m O ( m l o g 2 n ) O(mlog_2n) O ( m l o g 2 n )
区间修改update()
先找到具体区间,对该节点即以上的节点做修改,并给该节点打tag。下次经过某节点且该节点tag不为0,那么就要把tag[p]传递给左右子树,并清空tag[p],这个过程用push_down()函数完成。
模板(洛谷 P3372)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <bits/stdc++.h> #define ll long long using namespace std;const int N = 1e5 +10 ;ll a[N]; ll tree[N<<2 ]; ll tag[N<<2 ]; ll ls (ll p) {return p<<1 ;} ll rs (ll p) {return p<<1 |1 ;} void push_up (ll p) tree[p] = tree[ls (p)] + tree[rs (p)]; } void build (ll p,ll pl, ll pr) tag[p] = 0 ; if (pl == pr){tree[p] = a[pl];return ;} ll mid = (pl + pr) >> 1 ; build (ls (p),pl,mid); build (rs (p),mid+1 ,pr); push_up (p); } void addtag (ll p,ll pl,ll pr,ll d) tag[p] += d; tree[p] += d*(pr-pl+1 ); } void push_down (ll p,ll pl,ll pr) if (tag[p]){ ll mid = (pl+pr)>>1 ; addtag (ls (p),pl,mid,tag[p]); addtag (rs (p),mid+1 ,pr,tag[p]); tag[p] = 0 ; } } void update (ll L,ll R,ll p, ll pl,ll pr,ll d) if (L<=pl && pr<=R){ addtag (p,pl,pr,d); return ; } push_down (p,pl,pr); ll mid = (pl+pr)>>1 ; if (L <= mid) update (L,R,ls (p),pl,mid,d); if (R > mid) update (L,R,rs (p),mid+1 ,pr,d); push_up (p); } ll query (ll L,ll R,ll p,ll pl,ll pr) { if (pl >= L&&R >= pr) return tree[p]; push_down (p,pl,pr); ll res = 0 ; ll mid = (pl+pr)>>1 ; if (L<=mid) res+=query (L,R,ls (p),pl,mid); if (R>mid) res+=query (L,R,rs (p),mid+1 ,pr); return res; } int main (void ) ios::sync_with_stdio (false ); cin.tie (0 );cout.tie (0 ); ll n,m; cin >> n >> m; for (ll i=1 ;i<=n;i++) cin >> a[i]; build (1 ,1 ,n); while (m--){ ll q,L,R,d; cin >> q; if (q == 1 ){ cin >> L >> R >> d; update (L,R,1 ,1 ,n,d); } else { cin >> L >> R; cout << query (L,R,1 ,1 ,n) << '\n' ; } } return 0 ; }
以下是线段树模板类模板,目前是求区间和,以后会更新求区间最大值,最小值等等功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 #include <bits/stdc++.h> using namespace std;using ll = long long ;using ull = unsigned long long ;using pii = pair<int ,int >;using pll = pair<ll,ll>;using pull = pair<ull,ull>;using vec = vector<int >;using vecl = vector<ll>; using maii = map<int ,int >;#define pb(x) push_back(x) const int maxn = 2e5 +5 ;int a[2 *maxn];template <class T >class SegTree {private : vector <T> tree, tag; inline ll ls (ll p) return p << 1 ;} inline ll rs (ll p) return p << 1 |1 ;} void push_up (ll p) tree[p] = tree[ls (p)] + tree[rs (p)]; } void addtag (ll p, ll pl, ll pr, T d) tag[p] += d; tree[p] += (pr- pl + 1 ) * d; } public : SegTree (int n){ tree.resize (n << 2 , 0 ); tag.resize (n << 2 , 0 ); } void build (ll p, ll pl, ll pr) tag[p] = 0 ; if (pl == pr){ tree[p] = ::a[pl]; return ; } ll mid = (pl + pr) >> 1 ; build (ls (p), pl, mid); build (rs (p), mid+1 , pr); push_up (p); } void push_down (ll p, ll pl,ll pr) if (tag[p]){ ll mid = (pl + pr) >> 1 ; addtag (ls (p), pl, mid, tag[p]); addtag (rs (p), mid+1 , pr, tag[p]); tag[p] = 0 ; } } void update (ll L, ll R, ll p, ll pl, ll pr, T d) if (L <= pl && pr <= R){ addtag (p, pl, pr, d); return ; } push_down (p, pl, pr); ll mid = (pl + pr) >> 1 ; if (L <= mid) update (L, R, ls (p), pl, mid, d); if (R > mid) update (L, R, rs (p), mid+1 , pr, d); push_up (p); } T query (ll L, ll R, ll p, ll pl, ll pr) { if (pl >= L && pr <= R) return tree[p]; push_down (p, pl, pr); ll mid = (pl + pr) >> 1 ; T res = 0 ; if (L <= mid) res += query (L, R, ls (p), pl, mid); if (R > mid) res += query (L, R, rs (p), mid+1 , pr); return res; } }; int main (void ) ios::sync_with_stdio (false ); cin.tie (0 );cout.tie (0 ); int n; cin >> n; for (int i=1 ;i<=n;i++){ cin >> a[i]; } SegTree <ll> sgt (n); sgt.build (1 ,1 ,n); int l = 3 , r = 3 ; sgt.update (l, r, 1 , 1 , n, 5 ); sgt.query (1 ,n,1 ,1 ,n); return 0 ; }
并查集
将编号分别为1 ∼ n 1 \sim n 1 ∼ n n n n O ( 1 ) O(1) O ( 1 )
合并:合并两个元素所属集合(合并对应的树)
查询:查询某个元素所属集合(查询对应的树的根节点,也就是祖先),这可以用于判断两个元素是否属于同一集合
用并查集的基础操作完成HDU 1213
题目
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <bits/stdc++.h> using namespace std;int s[1005 ];int find_s (int x) return (x==s[x] ? x:find_s (s[x])); } void union_s (int a,int b) int x=find_s (a),y=find_s (b); if (x!=y) s[x]=s[y]; } int main (void ) ios::sync_with_stdio (false ); cin.tie (0 );cout.tie (0 ); int t; cin >> t; while (t--){ int n,m,a,b,sum=0 ; cin >> n >> m; for (int i=0 ;i<1005 ;i++) s[i]=i; for (int i=1 ;i<=m;i++){ cin >> a >> b; union_s (a,b); } for (int i=1 ;i<=n;i++) if (s[i]==i) sum++; cout << sum << '\n' ; } return 0 ; }
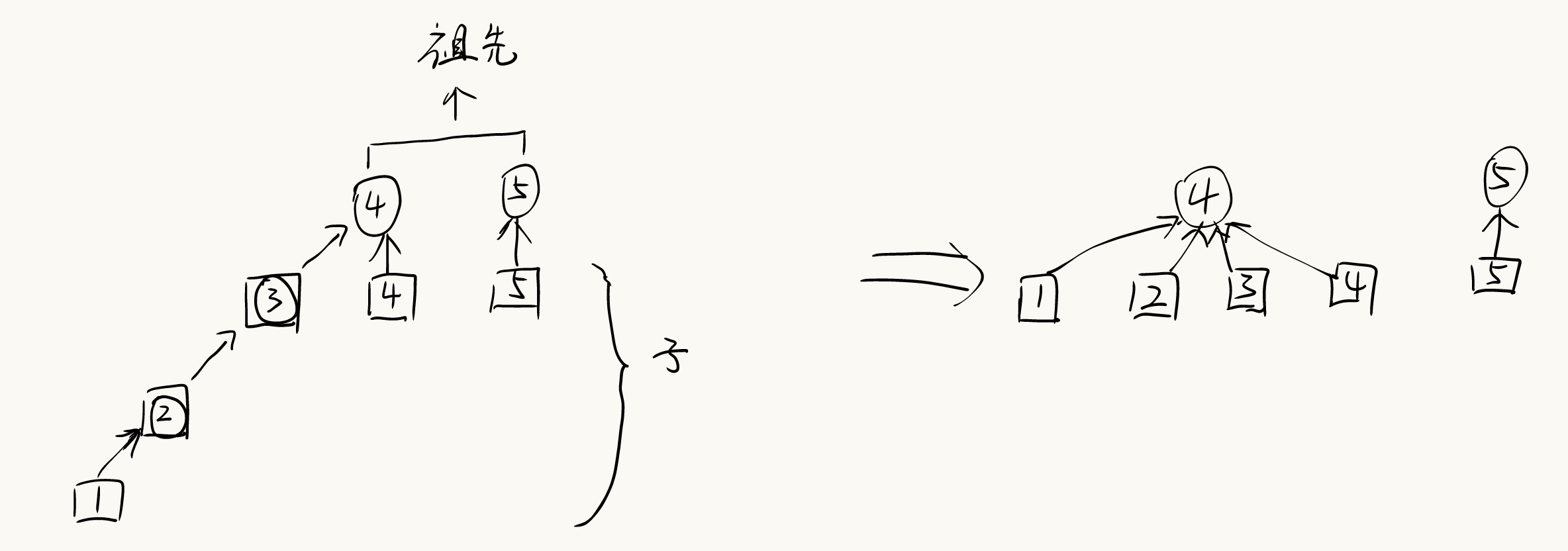
路径压缩
在合并过程中,树可能会发生退化,退成链表,增加查询的时间复杂度。通过路径压缩,将所有的子节点直接连到根节点,可大幅缩短搜索路径,加快查询,使树扁平化
1 2 3 int find_s (int x) return (x==s[x] ? x : s[x]=find_s (s[x])); }
按秩合并
这是合并的优化,我们让小集合的根指向大集合的根,这样更好一些。定义size[i]为以i i i
1 2 3 4 5 6 7 8 vector <int > siz (N,1 ); void union_s (int x,int y) x = find_s (x), y = find_s (y); if (x == y) return ; if (siz[x] > siz[y]) swap (x,y); s[x] = y; siz[y] += siz[x]; }
模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <bits/stdc++.h> using namespace std;const int maxn = 1e5 +5 ;vector <int > s[maxn], siz (maxn,1 ); void __init__(int n){ for (int i = 1 ;i<=n;i++) s[i] = i; } int find_s (int x) return (x == s[x] ? x : s[x] = find_s (s[x])); } void union_s (int x,int y) x = find_s (x), y = find_s (y); if (x == y) return ; if (siz[x] > siz[y]) swap (x,y); s[x] = y; siz[y] += siz[x]; } int main (void ) ios::sync_with_stdio (false ); cin.tie (0 );cout.tie (0 ); return 0 ; }
类版本模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class dsu {private : vector<int > s, siz; public : dsu (int n){ s.resize (n+5 ); siz.assign (n+5 ,1 ); for (int i=1 ;i<=n;i++) s[i] = i; } int find_s (int x) return x = s[x] ? x : s[x] = find_s (s[x]); } void union_s (int x, int y) int x1 = find_s[x], y1 = find_s[y]; if (x1 == y1) return ; if (siz[x1] > siz[y1]) swap (x1,y1); s[x] = y; siz[y] += siz[x]; } };
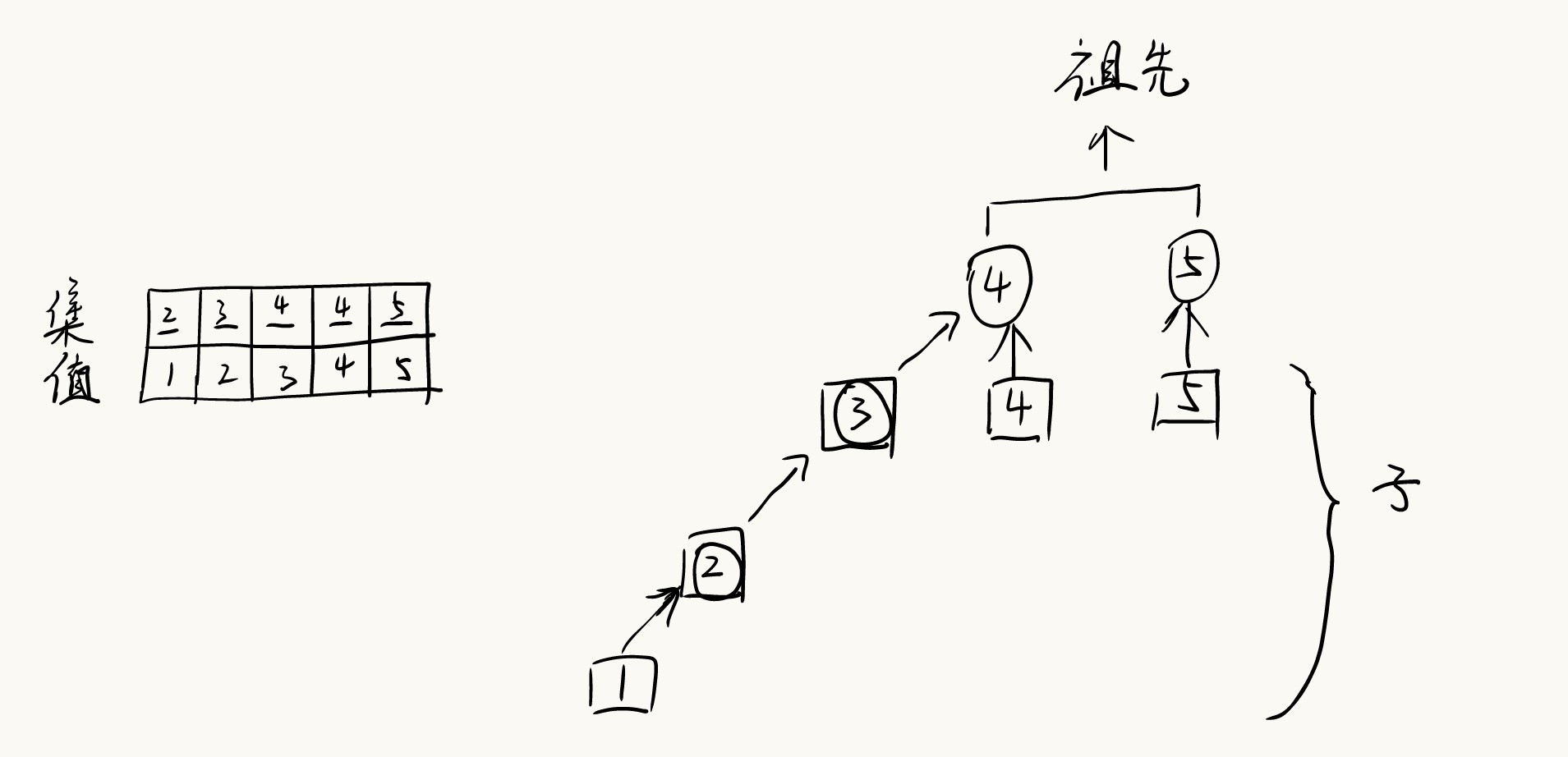
LCA
LCA(Lowest Common Ancestor)最近公共祖先,就是两个节点的公共祖先里面,离他们最近的那个祖先。
ST表倍增求解LCA
求解a,b两个点的LCA,你可能会想到暴力,这两个点一起,向它们的父节点跳,直到它们相遇,相遇的节点就是LCA。这种暴力的做法时间复杂度为O ( n ) O(n) O ( n )
既然一步一步跳太慢,那么我们可以通过二进制拆分 和倍增 思想,一次跳一大步。在预处理之后,它能够一次性向上跳 2 j 2^j 2 j j = 0 , 1 , 2 , . . . j=0, 1, 2, ... j = 0 , 1 , 2 , ... O ( n l o g n ) O(nlogn) O ( n l o g n )
我们定义:f [ i ] [ j ] f[i][j] f [ i ] [ j ] 节点 i 向上跳 2 j 2^j 2 j , d [ i ] d[i] d [ i ] 深度 。。
f f f
当 j = 0 时,fa[i][0] 就是 i 的父节点。
对于 j > 0,我们把"向上跳2 i 2^i 2 i i 向上跳 2 j − 1 2^{j-1} 2 j − 1 k;再从节点 k 向上跳 2 j − 1 2^{j-1} 2 j − 1
于是,我们就得到了状态转移方程:
f a [ i ] [ j ] = f a [ f a [ i ] [ j − 1 ] ] [ j − 1 ] fa[i][j] = fa[fa[i][j-1]][j-1]
f a [ i ] [ j ] = f a [ f a [ i ] [ j − 1 ]] [ j − 1 ]
这就是ST表 的做法,通过二分、倍增的思想来优化区间查询,时间复杂度为O ( m l o g n ) O(mlogn) O ( m l o g n )
总时间复杂度O ( ( n + m ) l o g n ) O((n+m)logn) O (( n + m ) l o g n )
以下是LCA模板题 洛谷P3379
P3379 【模板】最近公共祖先(LCA)
题目描述
如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先。
输入格式
第一行包含三个正整数 N , M , S N,M,S N , M , S
接下来 N − 1 N-1 N − 1 x , y x, y x , y x x x y y y
接下来 M M M a , b a, b a , b a a a b b b
输出格式
输出包含 M M M
输入输出样例 #1
输入 #1
1 2 3 4 5 6 7 8 9 10 5 5 4 3 1 2 4 5 1 1 4 2 4 3 2 3 5 1 2 4 5
输出 #1
说明/提示
对于 30 % 30\% 30% N ≤ 10 N\leq 10 N ≤ 10 M ≤ 10 M\leq 10 M ≤ 10
对于 70 % 70\% 70% N ≤ 10000 N\leq 10000 N ≤ 10000 M ≤ 10000 M\leq 10000 M ≤ 10000
对于 100 % 100\% 100% 1 ≤ N , M ≤ 5 × 10 5 1 \leq N,M\leq 5\times10^5 1 ≤ N , M ≤ 5 × 1 0 5 1 ≤ x , y , a , b ≤ N 1 \leq x, y,a ,b \leq N 1 ≤ x , y , a , b ≤ N 不保证 a ≠ b a \neq b a = b
以下是基于ST表的模板代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <bits/stdc++.h> using namespace std;using ll = long long ;using ull = unsigned long long ;using pii = pair<int ,int >;using pll = pair<ll,ll>;using pull = pair<ull,ull>;using vec = vector<int >;using vecl = vector<ll>; using maii = map<int ,int >;#define pb(x) push_back(x) #define eb(x) emplace_back(x) const int maxn = 5e5 +5 ;int n, m, s, a, b;vec e[maxn], d (maxn); vector <vector<int >> f (maxn, vector <int >(25 )); void dfs (int u,int father) d[u] = d[father] + 1 ; f[u][0 ] = father; for (int i=1 ;i<=20 ;i++) f[u][i] = f[f[u][i-1 ]][i-1 ]; for (auto v:e[u]) if (v != father) dfs (v,u); } int lca (int a, int b) if (d[a] < d[b]) swap (a, b); for (int i=20 ;~i;i--) if (d[f[a][i]] >= d[b]) a = f[a][i]; if (a == b) return b; for (int i=20 ;~i;i--) if (f[a][i] != f[b][i]) a = f[a][i], b = f[b][i]; return f[a][0 ]; } int main (void ) ios::sync_with_stdio (false ); cin.tie (0 );cout.tie (0 ); cin >> n >> m >> s; for (int i=1 ;i<n;i++){ cin >> a >> b; e[a].eb (b), e[b].eb (a); } dfs (s, 0 ); for (int i=1 ;i<=m;i++){ int x, y; cin >> x >> y; cout << lca (x, y) << '\n' ; } return 0 ; }